

Clinical Applications of Omics: The Latest Challenges
Disease and drug response testing from the bottom up
Converting omics data to diagnostics and prognostics involves extensive correlations and comparisons between data from normal and diseased states. Analyses include panels of proteins, genes, or metabolites numbering as few as three or four and as many as 20. Correlations forming the basis of decision making through statistical analysis of many samples over time, with each panel analyte having its own weighted significance, create a data deluge requiring specialized interpretive computing.
Seven Bridges (Cambridge, MA) provides software for large-scale genomic analysis, but Bryan Spielman, chief commercial officer, insists they are not a conventional bioinformatics company. “We employ about 90 bioinformaticians who understand the confluence of computer technology and biology. Where bioinformatics typically involves 80 percent data entry and 20 percent analysis, we flip those percentages.”
In November 2016, Seven Bridges announced integration of its genomic analysis software with functional interpretation software from SolveBio (New York, NY). Together, the computing platforms enable investigators to analyze and annotate large genomic datasets and refocus those results in the SolveBio platform for deep functional interpretation and assessment of potential clinical impact. Customers of both products may access the new capabilities through Seven Bridges’ public apps.
Related Article: New Study Reveals Major Racial Bias in Leading Genomics Databases
The need to analyze huge volumes of genomics data arose from national projects at major agencies, and later from big pharma to support first precision medicine and then conventional drug development. Clinical trials are a huge nexus, where drug developers look to define precise patient populations likely to benefit from small-molecule and biologic drugs. Spielman calls these efforts the “first wave” in genomics-based drug development. Genomics enables analysis among patient groups, forms the basis for obtaining an indication label, and helps uncover why molecules that succeed in phase 2 fail in phase 3. “The ability to characterize variances between patient groups is useful for expanding or narrowing label claims.”
Once genomics identifies ideal patient populations, the analysis is fine-tuned after the drug is marketed, when hundreds of thousands or millions of patients take the drug. FDA increasingly requires drug sponsors to initiate such studies to pinpoint patient subsets likely to experience toxicities. While genomic-based, end-to-end product stewardship is theoretically possible, Spielman notes that “we’re not there yet.”
Achieving that goal will require secondary analysis that goes beyond simple sequencing to interpretation that makes data more actionable, which is what the SolveBio deal is about. At stake is nothing less than the future prospects for personalized or precision medicine, both at the development stage (during clinical trials) and at the point of care.
This has been the predominant theoretical model for drug development. Spielman predicts that apart from dealing with infectious diseases, the one-size-fits-all (“blockbuster”) paradigm for treating chronic diseases will indeed disappear, but only through much deeper appreciation of the diagnostic and prognostic powers of omics, particularly genomics.
“It will take time to achieve cheap sequencing for everyone, to where even point-of-care diagnostics can drive treatment decisions. But the health care industry must leverage technology more strategically and immediately. They have the advantage of biology expertise, but a lot of pure ‘technology’ companies already possess the ability to analyze genomic data as it applies to treatment. Pharma must catch up on the technology side, or they’ll be facing a vastly different set of competitors.”
TAMING BIG DATA
Proteomic sample sets and data are becoming larger and increasingly unmanageable. In June 2016, SCIEX (Concord, ON) announced its next-generation proteomics (NGP) platform to automate and improve throughput while retaining performance and data quality that enable personalized treatments.
personalized treatments. One piece of NGP delivers large-scale quantitative proteomics through the company’s TripleTOF® 6600 system with SWATH® 2.0 Acquisition for quantitative proteomics combined with enhanced data processing and results visualization, retrospective analysis, and OneOmics™ cloud computing.
SWATH Acquisition has changed how SCIEX’s accurate mass systems analyze complex omics samples. “SWATH is a data-independent technique that allows the instrument to deliver quantitative fragmentation data for every detectable analyte in a complex sample—a major advantage over data-dependent methods,” explains Mark Cafazzo, director of academic and omics business at SCIEX.
Using data-dependent strategies, instruments might select a specific analyte for fragmentation in some samples but may ignore or miss it in others. Characterizing every peak across the sample set is essential for high-quality quantitation. SCIEX’s approach thereby solves the “missing data problem,” where analysts observe gaps in data for specific analytes across a sample set when using data-dependent acquisition. Such gaps, Cafazzo says, can affect the experiment’s quantitative precision.
“Let’s say that a study compares the proteomes of two large groups of biological samples, one representing healthy specimens, the other diseased. If your goal is to quantify just one analyte across these samples and you have a missing value, then that one sample is considered an outlier and excluded from quantitation.” But if the goal is quantifying thousands of proteins, which is more typical, many missing values will degrade overall quantitation. “SWATH treats every sample the same, regardless of the actual concentration of the specific analyte in any one sample.”
Genomics-based analysis consumes a lot of storage and computing resources. Analyzing a restricted panel of a few genes takes approximately 1 gigabyte per patient. Expanding that to the exome (protein-producing genes) raises the storage requirement to 15 gB. Whole-genome sequences take 100 gB. An Illumina sequencer can run 150 exomes every two or three days, which comes out to about 10 terabytes per month.
“Hospitals would have to purchase huge storage arrays to cover even exome sequencing for each patient,” notes James Hirmas, founder and CEO of Genome Next (Columbus, OH), which specializes in storage and computation for next-generation sequencing. “Computation and data transfer become unmanageable when a typical hospital can sequence one or two exomes every 12 hours. If yours is the 150th exome in the queue, it will take months to obtain results. The data itself has become the bottleneck.”
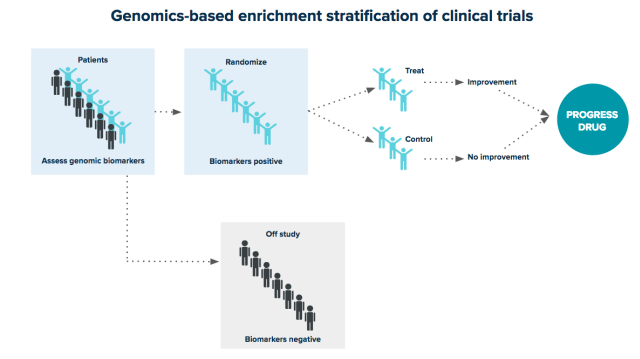 Not all drugs work equally well in all patients. By fully integrating genomic analysis into drug development, pharmaceutical organizations can define precise patient populations. In this example, selecting trial participants based on genomic biomarkers removes individuals likely to suffer adverse effects and maximizes the likelihood of trial success.
Not all drugs work equally well in all patients. By fully integrating genomic analysis into drug development, pharmaceutical organizations can define precise patient populations. In this example, selecting trial participants based on genomic biomarkers removes individuals likely to suffer adverse effects and maximizes the likelihood of trial success.
GenomeNext turns data storage and computation into a utility, in much the same way companies supply electricity or email services on demand. The company offers unlimited data storage, but the main benefit for personalized medicine is the “compute” component. Hirmas claims turnaround times for genomic panels of 30 minutes and for whole genomes in less than two hours, with up to 1,000 samples run simultaneously.
Hirmas says that non-genetic omics have only recently entered the clinical space and lag significantly behind germline and tumor analysis. “We can take on those data pipelines as well, but based on the market, the big need is for genomics, specifically exomes. Eventually the practice of running four or five panels on a patient will give way to routine whole-genome sequencing.”
SAMPLE PREPARATION
Sample preparation is another recurring theme in proteomics, where concentration dynamic ranges may be as broad as 1012 and matrix effects can predominate. Sample and standards preparation easily consume the lion’s share of analysis resources and become a significant source of systematic and one-off errors.
“As researchers scale up the size of studies, human factors in sample preparation will have a larger effect on the overall quantitative reproducibility,” Cafazzo comments. “Pipetting techniques, digestion protocols, and sample handling can vary greatly from one researcher to the next or one lab to another, and may influence the final result. That is the basis of the SCIEX partnership with Beckman Coulter on establishing standard configurations and liquid-handling and digestion protocols for operating Beckman’s Biomek automation workstations with SCIEX LC/MS systems.”
With actionable medical decisions being the ultimate goal, the stakes are much higher for proteomics research that underlie precision medicine than for R&D-type studies.
For proteomics supporting medical diagnosis, prognosis, or disease progression, investigators would like to compare the “active” state with baseline values from healthy populations and relapsed individuals or historical data from patients themselves. This work requires higher levels of reproducibility and greater sample throughput than typically associated with basic omics studies.
Additions to the SCIEX NGP platform therefore includes sample prep automation using the Beckman Coulter Biomek® NX, which automates manual, tedious steps for improved reproducibility.
NON-GENE OMICS
Analytical challenges for other omics disciplines are similar in principle to those of proteomics, but they differ operationally. Metabolomics, for example, analyzes small molecules that, depending on the sample type, typically present in a much narrower overall dynamic range.
“Metabolites pose other unique challenges in that their diverse chemical structures may require a variety of chromatographic separation techniques,” Cafazzo says. “And once [they’re] inside the mass spectrometer, the fragmentation of small molecules is subject to greater variability and generally provides less structural information than for proteins.”
Therefore, the ability to identify and quantify large numbers of analytes confidently, across increasingly larger groups of samples, is a common theme for the industrialization of omics in general.
Moreover, the numbers of endogenous metabolites of potential interest is still quite large when compared with non-omics applications, where investigators are often interested in a limited number of species.
“Continuously improving method robustness and reproducibility is always a priority, but the ways these goals are accomplished will vary based on specific workflows.”
Related Article: Scientists Devise New Approaches to Personalized Medicines
Personalized medicine has been described as the “right drug for the right patient at the right time” to achieve maximum therapeutic benefit with minimal side effects. Understanding individual differences in a drug’s safety and efficacy based on genetics, demographics, and environment has led to current thinking that many diseases once considered homogenous may require different treatments.
Omics are increasingly employed as predictors and indicators of drug response. While pharmacogenomics can accurately predict individual variations in drug response based on genetic polymorphisms, genotypes do not always predict phenotype, such as when a response is affected by demographics or disease progression.
That, says Piet van der Graaf, PhD, PharmD, VP at Certara (Princeton, NJ), explains interest in non-gene omics. For example, pharmacometabolomics studies the interplay between pharmacology and pathophysiology by measuring endogenous metabolites using analytical techniques like nuclear magnetic resonance spectroscopy and chromatography-mass spectrometry. “The potential advantage over pharmacogenomics is that they provide a direct readout of the state of each individual before and after drug treatment. They can be used to inform drug development to optimize individual pharmacokinetics (PK) and pharmacodynamics (PD) and as clinical diagnostics.”
Emerging techniques like quantitative systems pharmacology and quantitative systems toxicology (QSP/QST) are key enablers for applying omics in drug development. QSP/QST involve quantifying the dynamic interactions between drugs and biological systems, with the aim of understanding system behavior versus that of individual components. QSP/QST combine systems engineering, systems biology, and PK and PD for the study of complex biological systems through iteration between computational mathematical modeling and experimentation.
“It therefore allows integration of large and complex omics datasets into predictive models,” van der Graaf says.