
In recent years, the scientific community has increasingly looked at artificial intelligence (AI) as a tool that can deliver great benefits to operations and measurements that instruments undertake. Here, the basics of AI will be explained, as well as the potential benefits of implementing AI-based solutions to solve problems in labs.
First, let’s define a few terms you may have heard of: machine learning (ML) is the process to create AI. Machine learning can be applied through several different mechanisms, which include fuzzy logic, discriminant analysis, and neural networks. Due to their ability to process computationally intensive problems, neural networks are the basis of most commercially-viable AI tool.
The limit to implementing a neural network is simply the number of nodes, or possible connections, in the processor being used.
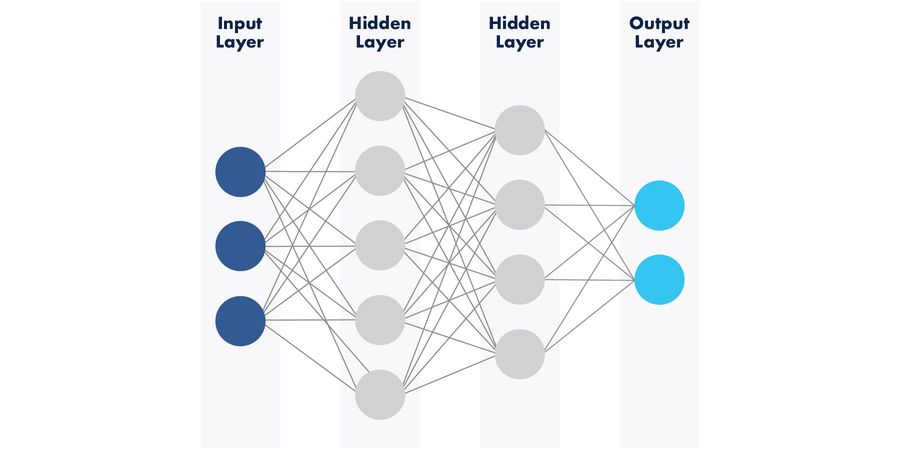
The nature of neural networks
To successfully apply an AI solution to a given problem, we must first characterize the problem. This is usually a mathematical solution to a specific problem of analyzing data, such as a smoothing algorithm, or data trend identification. In designing a neural network, the network is constructed of a number of “layers” where each represents a separate mathematical operation. The combination of these functions on a data stream allows for data features to be extracted. This might be the useful answer that is sought, or it might be an intermediate stage that undergoes further processing. For example, a network may establish two or three different ways of averaging a given set of data. The outputs could then be fed to a comparator, which selects the best fit answer from the three presented to it, based on percentage probabilities of it being correct.


In creating the neural network, it will initially act as a “black box,” meaning that within the network, there are no pre-determined nodal interconnections; no nodes or possible paths through the network have been assigned weights or biases. This is the starting point for the AI.
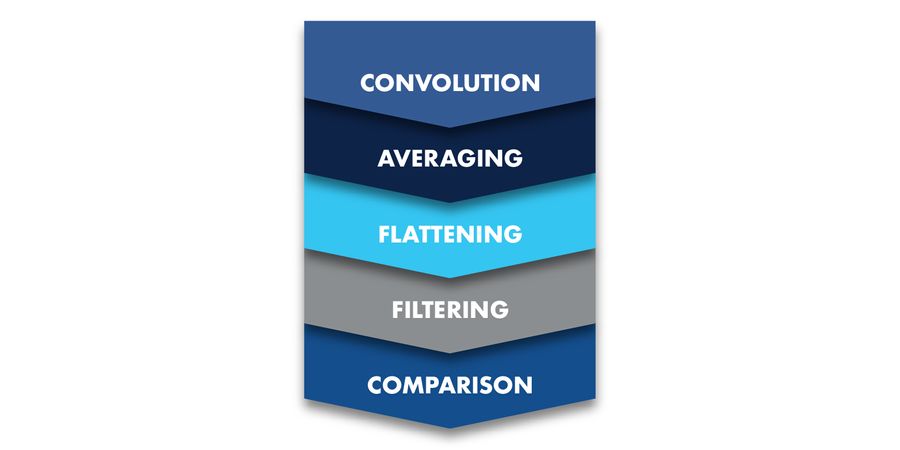
Determining the dataset to be used is critical to the characterization of the problem that will be solved using AI. For example, it could be a .PNG image file generated by an instrument indicating the presence or absence of a sample tube in a rack, but any data set could be the starting point. AI is particularly useful for image analysis and has found application in histocytology for the determination of cervical cancer cell types in smear tests. The AI algorithm has been shown to be nearly 100 percent accurate in identifying potential tumor cells .
The input layer of the neural network is defined by the size of the input data stream. In the above example, it might be an eight-bit, 50 x 50-pixel image where each pixel has a possible value between zero and 225. Each layer that this data is fed through, in sequence, is a separate mathematical argument. The combination of the mathematical functions yields an overall greater function, such as image classification.
The role of the classification network is to decide, or classify, the content of the image according to a pre-determined set of parameters. For example, is the output zero, one, or greater than one? It could also be a simple yes/no answer, or in the example above, is a tube present or not? In this case, the classification network produces two answers—the probability of the image containing a tube and the probability the image does not contain a tube. The output is fed to a comparator that examines the result and yields the answer to the question: does the image contain a tube? If the network is wrong, then it must be “re-trained.” In a sophisticated network, techniques such as the Adam function may be used to explore an area of solution space—in graphical terms, the area which is bounded by the locus of all possible valid solutions to the mathematical arguments.

Lab Management Certificate
The Lab Management certificate is more than training—it’s a professional advantage.
Gain critical skills and IACET-approved CEUs that make a measurable difference.
In practice, the network is “trained” by presenting it with large numbers of known examples, usually many thousands. Control of a neural network allows the network to adjust the weights and biases of each node to “grow” the network in a direction that more closely resembles the allowed solutions. In the provided example, the network is presented with thousands of different tubes. The network adjusts itself until, eventually, it can discriminate between a good and a badly imaged tube. With further training, it can determine if no tube is present at all. That sounds obvious and easy, but in practice, many factors in the lab, such as overhead illumination, proximity to windows, time of day, and reflections from adjacent populated wells can all cause the imager to perceive a tube where in fact, none is present.
The importance of data verification
Once trained, the network must be verified. A verification set of data, approximately 20 percent of the size of the training set, containing new, relevant images is used to score the performance of the network.
Interested in lab leadership?

In practice, networks can have a tendency to be over-trained, such that they are marvelous at processing the training set, but fail miserably when presented with new data. To mitigate this over-training problem, a number of techniques can be employed, such as augmenting the training data and forcing the partially trained network to lose current values of weights and biases. Data augmentation allows developers to perform transformations, rotations, and other image pre-processing operations on their training set. By augmenting the data, it is ensured that the variety of images used by the network for training is increased, hence lowering the tendency to create an over-trained network.
Dropout is a second process to help reduce over-training; where a percentage of the trained weights/biases are randomly removed between training epochs. the neural network then must re-learn the weights when it is presented with another iteration of the training data. Success in preventing over-training is achieved, when the network is presented with brand new data and is able to score just as highly when compared to the training set. Once a network performs in this way, it is considered ready for deployment.
There are a number of frameworks that can be used for the development and training of neural networks, such as Tensorflow, PyTorch, Torch, and Keras.. The frameworks run using common programming languages such as Python. These provide an end-to-end, open-source platform for machine learning with a suite of tools and libraries that let developers easily build and deploy ML-powered applications, such as scientific image analysis.
Ultimately, once a neural network has been fully trained, the next step is to move it onto an FPGA, or field-programmable gate array. This device combines billions of transistors into a platform from which custom architectures can be created to solve the user-specific problem. FPGAs have a number of advantages over other processing technologies; they provide a flexible platform with the ability to update its configuration in the field, they yield a high performance compared to other processors, and they allow for rapid development turn-around compared to custom silicon. Translating the neural network in this way will determine the architecture, size, capacity, and cost of the FPGA. Most FPGAs can still run many times faster than the embedded PC used to address them, so an even bigger, more powerful network could be accommodated at a future point, if required.
As noted above, ML is beneficial for certain image analysis problems. It can identify features at very high resolution that the human eye would find difficult to resolve. In addition, deconvolution of over-lying data, such as spectra or chromatograms, lend themselves to an AI solution. In the lab, potentially any large data set that requires pattern recognition could be undertaken by AI. In other areas, methods are in development that will reduce the amount of training data needed to condition a neural network, making their application easier and quicker. The promises of AI in the lab are faster, more sensitive, and cheaper data-processing than what is possible today.






