
Designing an R&D IT infrastructure to support chemicals and materials innovation is not an easy task. The challenge is to reconcile the requirements of very specific innovation processes with commercially available systems. Architects that pick and choose digital point solutions for specific data management tasks often hit limitations, because from an evolutionary perspective, these systems were initially designed for life sciences applications. This has some far-reaching implications that go beyond the question of what commercially off-the-shelf system is the best for solving a specific data management problem.
Highly diverse workflows and data types
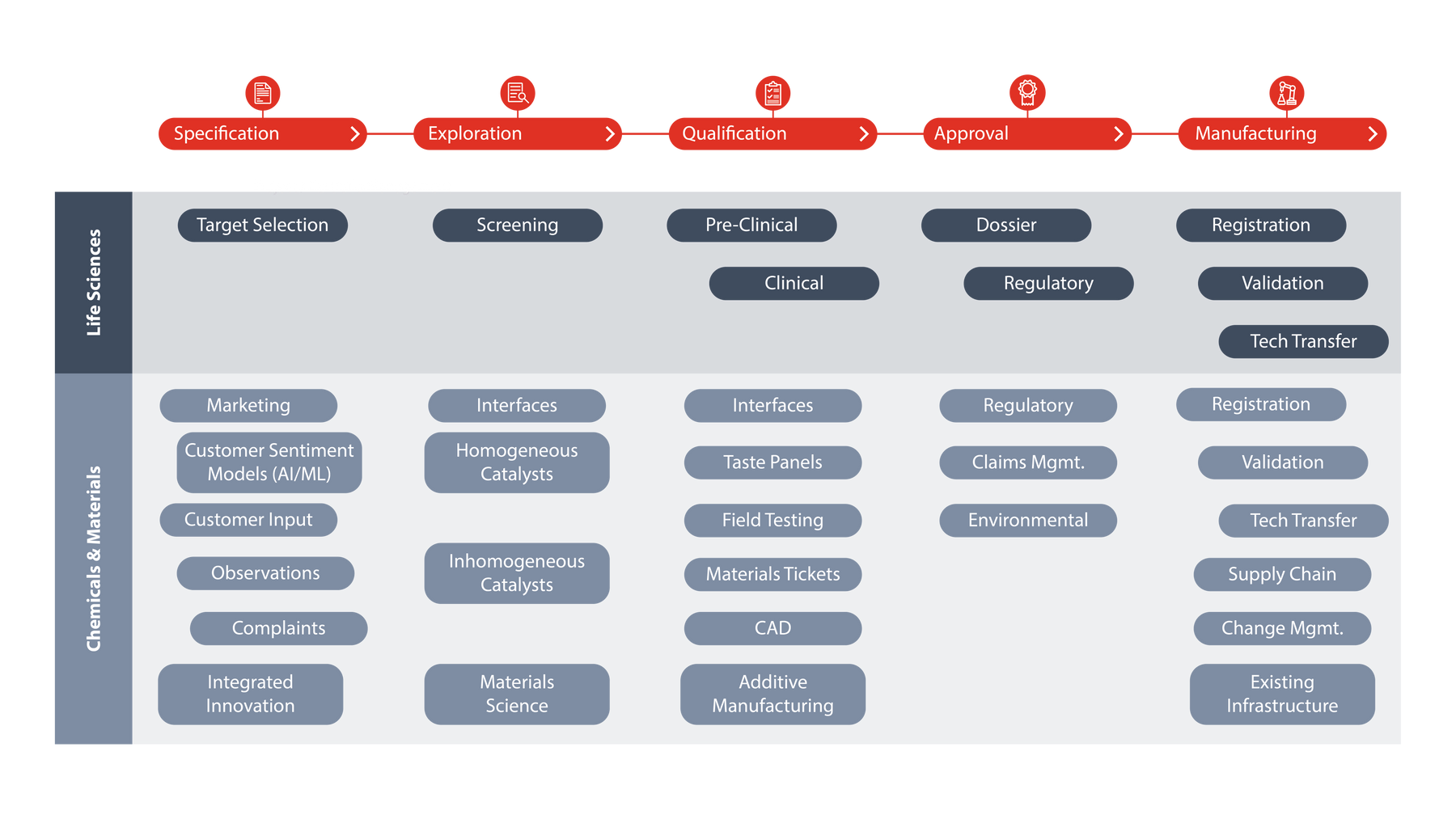
While there are commonalities with R&D digitalization in life sciences, there are some key differences that have far reaching implications for infrastructure design in chemicals and materials R&D. The main reasons for this are that the highly standardized R&D workflows in life sciences have strikingly diverse counterparts in chemicals and materials R&D. Furthermore, life sciences workflows vary little across companies, yet a polymer research workflow could be implemented differently by two separate companies.
Another key difference comes from the types of data these workflows generate. Again, chemicals and materials produce a much more diverse set of data that is often stored in specialized, custom systems. Examples include R&D data stored in flavor tasting panel results in flavor and fragrances research, to literal road testing results in tire manufacturing.
Beyond connecting instrument data to samples
In its most narrow sense, lab data automation is about automatically ingesting data from instruments and connecting them to the samples that were used to produce the instrument data in the first place. This alone is a tremendous benefit for lab operations, both in terms of productivity gains and increased data compliance. Lab technicians don’t have to manually transfer data from instruments and into databases as analytical data can be automatically parsed and processed. This further reduces the need for repetitive processing time and ensures human created errors are not introduce into the data. Additionally, parsing means that instrument data can be stored in an instrument-agnostic form, which greatly enhances data longevity. Previously, long-term data retention has been strongly dependent on the availability of appropriate vendor software to read these data.

Advanced Lab Management Certificate
The Advanced Lab Management certificate is more than training—it’s a professional advantage.
Gain critical skills and IACET-approved CEUs that make a measurable difference.
Lab data automation in the broader context of R&D digitalization–blurring the boundaries between LIMS, SDMS, and ELN
What does lab data automation mean in the broader context of R&D digitalization? For many organizations, data-driven R&D has become a strategic goal, and while being able to automatically attach instrument data to sample data is an important piece of the puzzle, it certainly does not achieve the goal of getting data to scientists faster. To understand the problem, here is a snapshot of a traditional R&D IT infrastructure designed from a collection of systems, each one designed to solve very specific tasks.
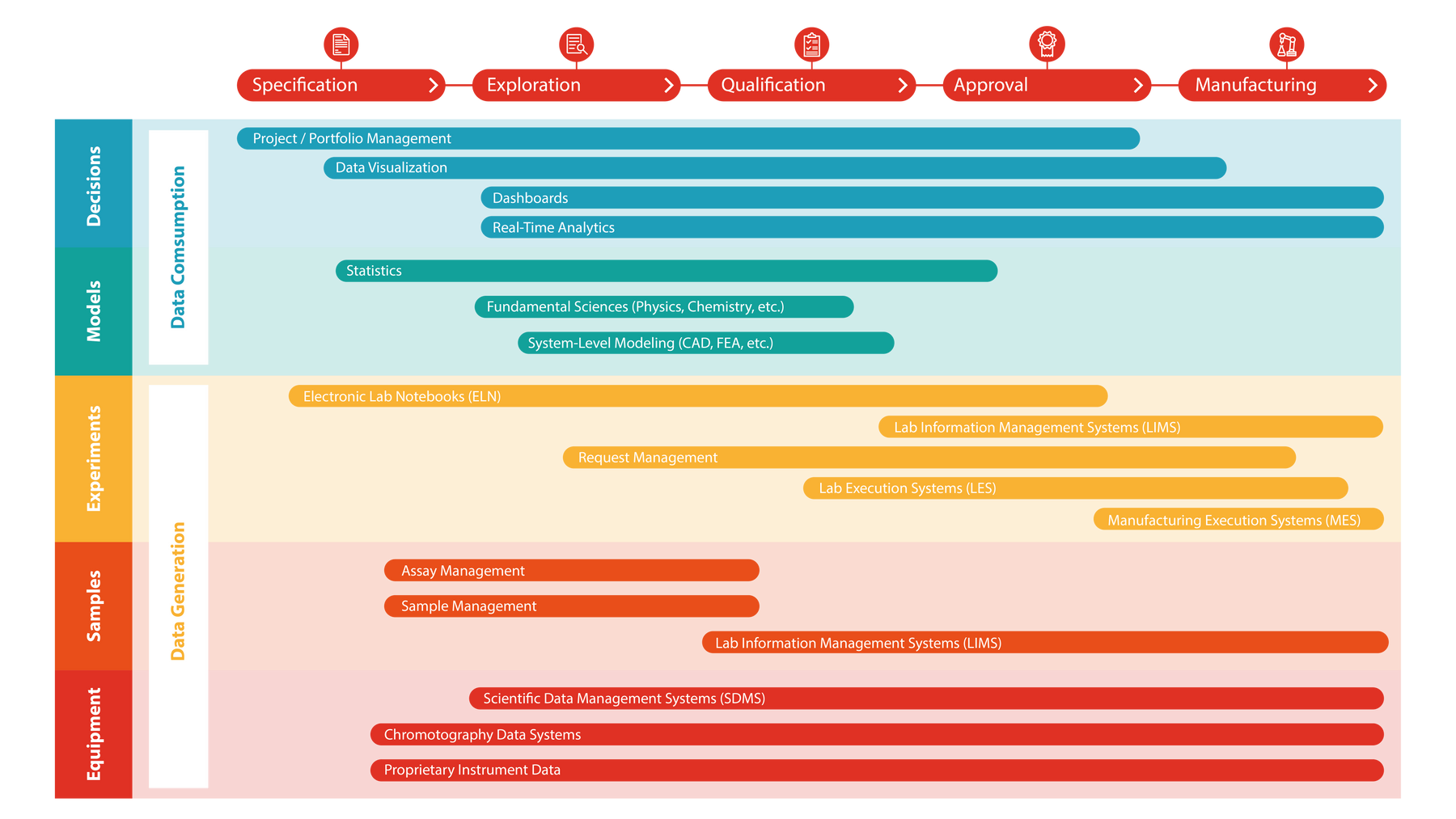
Generally speaking, the systems can be divided into two main categories: data generators and data consumers. Or in simple terms, “data in” and “data out” systems. If the ultimate goal is to get data to scientists faster, “data in” and “data out” systems need to be tightly integrated. While this might be achievable at the system level, this is best done in a unified platform approach, described by Gartner, a leading research and advisory firm. As discussed elsewhere, there are implications on data-driven R&D, especially for chemicals and materials. But how does a unified platform carry out the tasks within lab informatics, especially if we are thinking in terms of familiar systems like lab information management systems (LIMS), scientific data management systems (SDMS) and electronic lab notebooks (ELN)?
Interested in lab design?
In broad terms: an SDMS is responsible for acquiring and aggregating instrument data; a LIMS system is used for tracking samples and attaching data records to it; and an ELN is used for capturing experimental observations. Whilst this may be highly oversimplified and many systems today blur the boundaries of what each systems can do, it hopefully illustrates that for understanding the full R&D data context, information from each of these systems is needed.
Using the unified platform approach, these systems do not exist. Instead, there are capabilities within the platform that perform the tasks of these individual systems. For example, sample and request management systems are often within the domain of a LIMS system. In the unified platform, these capabilities also exist, but they are configured into a workflow that passes sample information back and forth between analytical labs and scientists. The major advantage of the unified platform is that all data work within a common data model. Or in layman’s terms, the scientist that receives the sample data can draw conclusions, annotate experiments, and all this information is now connected and can be shared and utilized by all colleagues.
The other major advantage of a unified platform lies in the fact that workflows and roles can be easily configured. This means that everyone in the organization engages in the R&D infrastructure because it aligns to their ways of working, in contrast to groups having to conform to rigid systems. As mentioned above, chemicals and materials workflows are highly diverse and vary from company to company, making the unified platform approach especially attractive.






